Lauren Jung, Grace Lee, Sharii Liang, Felicity Ryan, Christina Tan
In an increasingly global society, the presence of loanwords, also known as words adopted from a foreign language, is more common than not. However, these words often lose their original pronunciation in the process due to incompatible phonemic inventories. But what if a person is bilingual in both the origin language and the adoptive language? Which pronunciation should be elicited? We see bilinguals answer this question daily, picking and choosing between the native and adapted pronunciations of loanwords in conversation. In this article, we analyze the reasons behind their decisions to code-mix versus phonologically adapt through the lens of group identity. Specifically, we investigate the potential role shared ethnic identity has on English-dominant L1 speakers and heritage speakers of Mandarin Chinese and Korean. Utilizing a structured double interview format, our work simultaneously corroborates and revises an existing theory about the purpose of code-switching with larger implications about perceived belonging in today’s society.
Keywords: group identity, code-switching, community, bilingualism
Introduction
The ways in which speakers structure their speech is very much linked to their conversational environment. Driven by social factors like linguistic identity, ethnicity, and societal perceptions of status or education, interlocutors alter aspects like phonology or prosody to improve communication or address societal expectations. For example, in a room full of children, we might speak in a higher pitch and with significantly less expressive (read: expletive) speech. This extremely common phenomenon is known as linguistic adaptation. When it comes to bilinguals, this can manifest as phonological adaptation in even the most basic of interactions:


Unfortunately, as seen in the above images, such adaptations are not always well-received. So how do bilinguals decide the most fitting pronunciation for any given situation? In this project, we notice that it is often not a choice by the interlocutor but a reaction to the listener.
Background
Code-switching (CS) is a phenomenon observed in multilingual speakers defined as “the process of mixing two or more languages within a discourse, or even within a single utterance” (Wintner et al., 2023). From a phonological perspective, CS has the potential to evoke certain attitudes toward the speaker as it is correlated with lesser perceptions of possible education level, income, citizenship status, etc. depending on the demographic of the interlocutor (Carr, 2014). For these reasons, people may or may not choose to code switch and instead opt for phonological adaptation (PA). Defined as the alteration of a loanword’s phonemes to fit into the existing sounds of the recipient language, it is often more than a simple response to phonemic inventory limitations; PA can also be in response to pressures like social context and the need for more efficient communication (Lubyan and Dale, 2016).
At UCLA, some of the most spoken non-English languages are Mandarin Chinese and Korean. Of the 6,300+ undergraduate international students alone, 52% speak Mandarin Chinese while only 9% speak Korean. These students not only make up a large proportion of the international student population but the domestic population as well. Thus, despite the English-dominant setting of an American college campus, it is not rare to hear Mandarin Chinese or Korean spoken between classes. Yet, within the classroom, Mandarin Chinese and Korean bilinguals resort to PA more than CS even when discussing personal topics like their hometown.
Despite increasing research on bilingualism and code-switching, the majority of the work has centered around the effects of code-switching. One of the proposed functions of CS is to mark “speakers with others in specific situations (e.g., defining oneself as a member of an ethnic group)” (Johnson, 2000, p. 184, as cited in Gudykunst, 2004). Our project aims to address the other side of the conversation: the causes of code-switching. Considering the sociopolitical relationships between the U.S. and China, which is generally negative, and the U.S. and Korea, which is generally positive,bilinguals may actually be influenced towards CS or PA based on their perception of rapport with the listener. More specifically, how does the social and linguistic identity of the listener modulate the interlocutor’s rate of code-switching? In this project, we argue that CS is more likely when the interlocutor perceives the target as being a part of their ethnic identity, showing that CS is more of a reaction than an action.
Methods
Our work discussed personal topics such as food, place, and cultural identity with 17 English-dominant bilingual UCLA students. Group members asked questions such as “What city are you or your family from?” and “Do you have any cultural foods you miss/enjoy?” 9 spoke Mandarin as the other language, and 8 spoke Korean. Each participant underwent two identical, 5-10 minute virtual interviews in English but with different interviewers. Conducting the interviews with cameras off allowed our interlocutors to use aliases. After each interview, we sent a survey discussing which language was most dominant in their daily lives and their perception of the interviewer’s approachability. Because of the lack of video, this perception would be based solely on the alias.
This design allowed us to focus on the differences in CS frequency within participants (i.e. a single participant’s elicitations between interviewers) and between groups (i.e. the average elicitations of Chinese bilinguals compared to Korean bilinguals). As a part of our focus was beyond purely linguistic research, we also looked to tie our results into sociopolitical tensions and societal feelings about certain nationalities. Our participants consisted of both heritage speakers and L1 speakers of Chinese or Korean. The diversity of our participants provided multifaceted insights into the factors driving CS by also noting the impact lifelong language dominance has and how that ties into the interplay between linguistic and social identity.
Results and Analysis
Our results were quite explicit about the positive correlation between increased societal standing and frequency of CS. We observed a clear difference between Chinese and Korean bilinguals in their rates of CS in the monolingual condition as reflected in the two interview snippets below:
Bolded = CS
Chinese Bilingual
| PARTICIPANT: My family is from Hunan.
| INTERLOCUTOR 1: Hunan? Ooh, okay.
Korean Bilingual
| PARTICIPANT: Um, I believe they were born in Seoul, the capital.
| INTERLOCUTOR : Seoul. I see.
When speaking to a monolingual, Korean bilinguals had a tendency to code-switch and then translate or explain the word. In comparison, Chinese bilinguals favored phonological adaptation. When that would not work, often seen with naming their favorite cultural dishes, they resorted to direct translation and had to be prompted by the interviewer for the Chinese name:
Chinese Bilingual
| PARTICIPANT: I really like… uhm, sweet and sour pork.
| INTERLOCUTOR 1: Sweet and sour pork? Is there a word or specific name for it in Chinese?
| PARTICIPANT: Yea, it’s called tang cu pai gu.
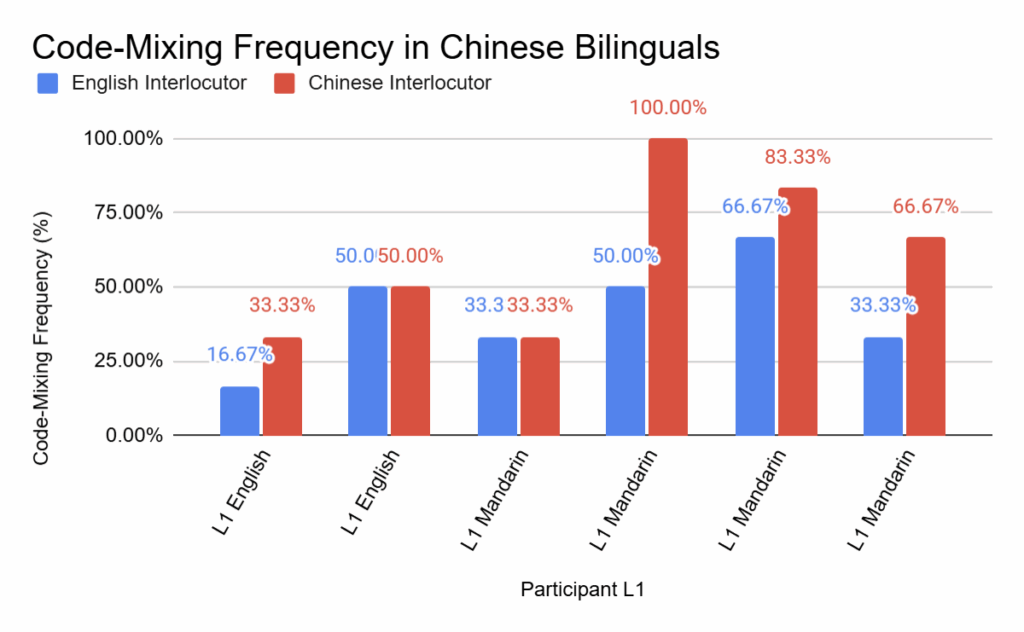
In the bilingual interviewer conditions, we saw increased amounts of CS for L1 and heritage speakers of all groups. However, the largest change could be seen in the L1 Chinese speakers with an average 33% increase in code-switching. Using a paired t-test, we identified if these differences in the frequency of CS between the monolingual interviewer and the bilingual interviewer conditions per language group were significant.
Because of the higher tendency to CS in Korean bilinguals, there was no significant difference found between the first interviewer and the second interviewer for both heritage and L1 speakers (p = 0.085):
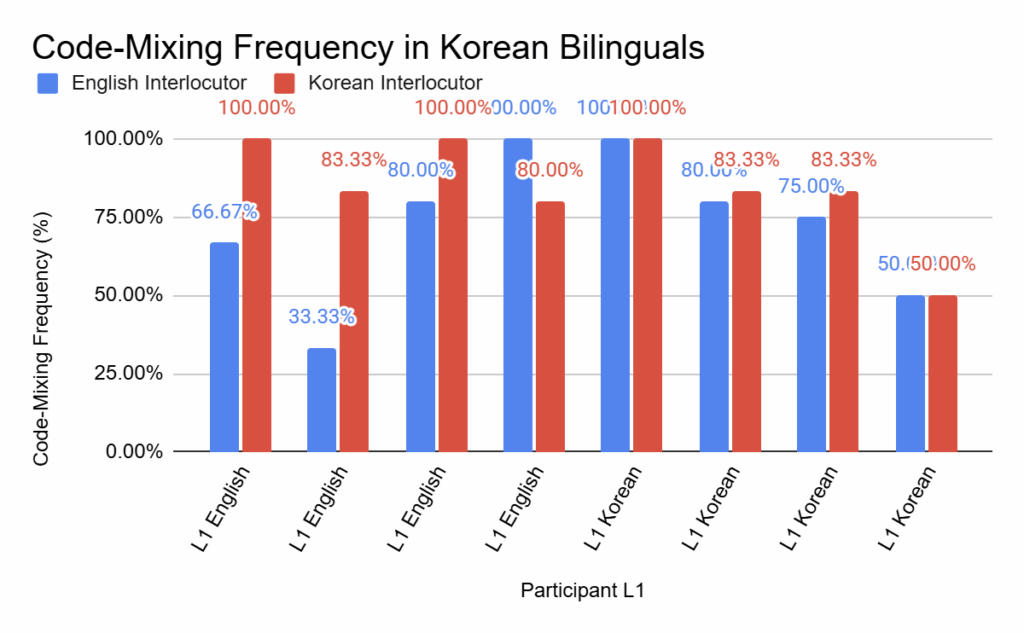
However, Chinese bilinguals were significantly different between interviewers (p = 0.029):
Due to our post-interview survey, we could isolate linguistic and social identity factors to see if there was any correlation. In terms of linguistic identity, participants rated their daily use of the non-English language on a scale of 1-5 with 5 being daily and 1 being almost never. They also rated their own fluency on a scale of 1-5 with 5 being fluent or native. Korean bilinguals averaged higher on both usage and fluency (4.625 and 3.75, respectively) compared to Chinese bilinguals (4.14 and 3.28, respectively), illustrating a trend where more frequent usage and higher fluency contributed positively to the utilization of code-switching. These are important factors that play a role in an individual’s perception of their own linguistic identity.
Socially, we asked participants to vote on the approachability of their interviewer and provide a brief rationale for their answer. The following word clouds revealed trends about factors that matter the most to Chinese and Korean bilingual speakers that may have modulated, whether consciously or unconsciously, their pronunciations:
English Monolingual Interviewer

Chinese Bilingual Interviewer

Korean Bilingual Interviewer

For the monolingual English interlocutor, mentions of an understanding of the participant’s ‘culture’ were equal to mentions about disposition. 7/14 voted ‘YES’ to the interviewer being approachable. For the Chinese interlocutor, there was a heavier focus on disposition. 6/6 that voted ‘YES’ mentioned how ‘nice’ the interviewer was. For the Korean interlocutor, there was a heavy focus on cultural understanding. 7/8 voted ‘YES’ to the interviewer being approachable.
These patterns and the sharp uptick in approachability rating for the bilingual interlocutors, solely through a name change, signal that the social identity, specifically the ethnic identity, of the listener seems to play a larger role in code-switching than previously thought.
Discussion and Conclusion
By changing the interlocutor’s alias to align more with the participant’s social identity, we found that code-switching did occur to mark group membership, as previous literature has theorized, but that it occurs as a reaction to a fellow group member who has already come out rather than as an action to identity oneself and find similar members. This may be why Mandarin Chinese and Korean are heard so abundantly outside of the classroom. Students establish friend groups with similar social identities and revert back to the language that marks them as a member of said group and excludes most outsiders.
While the results observed in our research thus far have been promising, there are still several considerations to be made. One limitation arose in the fact that we failed to anticipate other ways participants may respond to questions. We framed them in a way that would most likely evoke a response in a non-English language, but interviewees would sometimes directly translate answers or use cognates. In the below example, the participant opted to use colloquial terms to describe the food, and only referenced the term in Korean when prompted.
BOLDED: Code Switching
Korean Bilingual
| INTERLOCUTOR: Do you have any cultural food you miss or enjoy besides Sundubu?
| PARTICIPANT : I would probably say, when I am craving it, it would probably be kimchi stew
that my mom makes, yeah.
| INTERLOCUTOR: And what’s the, what would be the name of that in Korean?
| PARTICIPANT: Kimchijiggae
Additionally, the hope would be to represent the population of Mandarin Chinese- or Korean-speaking bilinguals at the University of California, Los Angeles, but we must take into account the low external validity of our study. We did not randomly sample the 17 participants; we instead relied on direct connections and snowball sampling. Apart from the sampling method, this sample size represents only a fraction of the total number of students that speak Mandarin Chinese or Korean at UCLA. Reasons for this include the smaller number of Korean speakers on campus with only 9% of 6,300+ undergraduate international students speaking the language, even when not accounting for non-international undergraduate students, and the narrow framework we used to define L1 speakers. We did not consider those who had learned Chinese or Korean as their L1 but lost the language growing up to be L1 speakers for the purposes of our analysis. A future study can make note of and address these limitations in a variety of ways such as implementing a different sampling method with more discretion given to the participants’ complex language background and potentially narrowing the participant parameters so as to be able to draw clear correlations. Furthermore, we would want to ensure that there is an even balance between participants in each condition with random assortment of ages and gender to prevent any confounding.
It is important to note that our research, while on the surface an introductory envoy into the world of codeswitching and sociolinguistic research, seeks to begin to tackle the real world impacts on communication that have been foisted upon non-English speaking individuals and communities as a result of xenophobia and racism. It builds upon the work of researchers like Dr. Okim Kang and Dr. Donald L. Rubin who investigated the presence of reverse linguistic stereotyping in environments where the only factors at play were the speaker’s ethnicity – as surmised by their given name and visual appearance (Okim & Rubin, 2009). Unlike linguistic stereotyping which is based on the observed differences in one’s speech, RLS is the assumption of perceived linguistic deficiencies based solely on the speaker’s ethnicity, name, and/or appearance.
Dr. Kang and Dr. Rubin’s research was a more formal version of what Dr. Baugh from Emory was trying to investigate in his informal research into linguistics stereotyping, in his case in the context of acquiring housing (Baugh, 2019, 08:28). See his TedxEmory Talk for real world impacts. While our own research participants were in a relatively low-stakes environment, speaking with someone of similar age, they still chose to make phonological adaptations in order to be better understood or perhaps to not risk the occurrence of any manner of linguistic stereotyping. Without further research, we are not able to draw any direct conclusions but the correlations do begin to emerge which makes us wonder what can be done to inhibit such stereotyping and ensure that people of all levels of language proficiency are not discriminated against?
In conclusion, our research sheds light on the intersection of culture and language. Language choices can be used to mark membership of a group via both inclusion and omission. Although people often reference culture, language, and race in a way that seems interchangeable, all three are facets of individual identities. Even well-meaning individuals can appreciate one or two while not acknowledging another. This is the importance of both social and linguistic justice.
Our work demonstrates that even as minority cultures become more mainstream, bilinguals still require a sense of community and safety before fully expressing themselves in their non-English language. For more on the importance of linguistic justice and representation, see this TedX talk by Malaka Grant: Why language shapes identity (more than race).
Ultimately, our findings stress the importance of diverse representation on English-dominant campuses and environments in general, particularly for groups whose ethnic and national identities are sociopolitically at odds with one another, so that we may all live in a more linguistically and socially just society.
References
Antoniou, M., Best, C. T., Tyler, M. D., & Kroos, C. (2011). Inter-language interference in VOT production by L2-dominant bilinguals: Asymmetries in phonetic code-switching. Journal of Phonetics, 39(4), 558–570. https://doi.org/10.1016/j.wocn.2011.03.001
Baugh, J. (2019, February). TEDxEmory: The Significance of Linguistic Profiling [Video]. TED. https://www.ted.com/talks/john_baugh_the_significance_of_linguistic_profiling
Chang, C. B. (2012). Rapid and multifaceted effects of second-language learning on first-language speech production. Journal of Phonetics, 40(2), 249–268. https://doi.org/10.1016/j.wocn.2011.10.007
Charisse, R. (2017). One margarita, please! Language attitudes regarding pronunciation in the language of origin. Voices, 2(1). https://escholarship.org/uc/item/3jk6z6tt
Gudykunst, W. B. (2004). Bridging differences : effective intergroup communication. Sage Publications.
Hwang, J., Brennan, S. E., & Huffman, M. K. (2015). Phonetic adaptation in non-native spoken dialogue: Effects of priming and audience design. Journal of Memory and Language, 81, 72–90. https://doi.org/10.1016/j.jml.2015.01.001
Kang, O & Rubin, D. (2009). Reverse Linguistic Stereotyping: Measuring the Effect of Listener Expectations on Speech Evaluation. Journal of Language and Social Psychology. 28. 441-456. https://doi.org/10.1177/0261927X09341950
Lupyan, G., & Dale, R. (2016) “Why Are There Different Languages? The Role of Adaptation in Linguistic Diversity.” Trends in Cognitive Sciences, vol. 20, no. 9, Sept. 2016, pp. 649–660, https://doi.org/10.1016/j.tics.2016.07.005
Shore, P. (2026, January 22). Authenticity of pronunciation. Language Log. https://languagelog.ldc.upenn.edu/nll/?p=72656
Shore, P. (2026, January 19). A better pronunciation of “Davos”. Language Log. https://languagelog.ldc.upenn.edu/nll/?p=72643
Stollznow, K. (2026, February 26). It’s never too late to learn a language – adults and kids bring different strengths to the task. TheConversation.https://doi.org/10.64628/AAI.d4nryq5fw
TEDx Talks. “Why Language Shapes Identity (More than Race) | Malaka Grant | TEDxGeorge.” YouTube, 22 Dec. 2024, www.youtube.com/watch?v=3nKPLdZx8RY.
Wintner, S., Shehadi, S., Yuli Zeira, Osmelak, D., & Nov, Y. (2023). Shared lexical items as triggers of code switching. Transactions of the Association for Computational Linguistics, 11, 1471–1484. https://doi.org/10.1162/tacl_a_00613